1 基本概念
-
在Java底层源码中,String 类被final修饰,不可以被继承

-
字符串是常量
- Q1:思考一下,使用字符串字面量String string声明对象和使用new关键字string创建对象有什么区别呢,如果给这两个对象赋相同的值,他们的地址会相同吗,为什么?
Q2:为什么作为常量的字符串可以被再次被"赋值"呢
这就要从字符串的内存图说起:
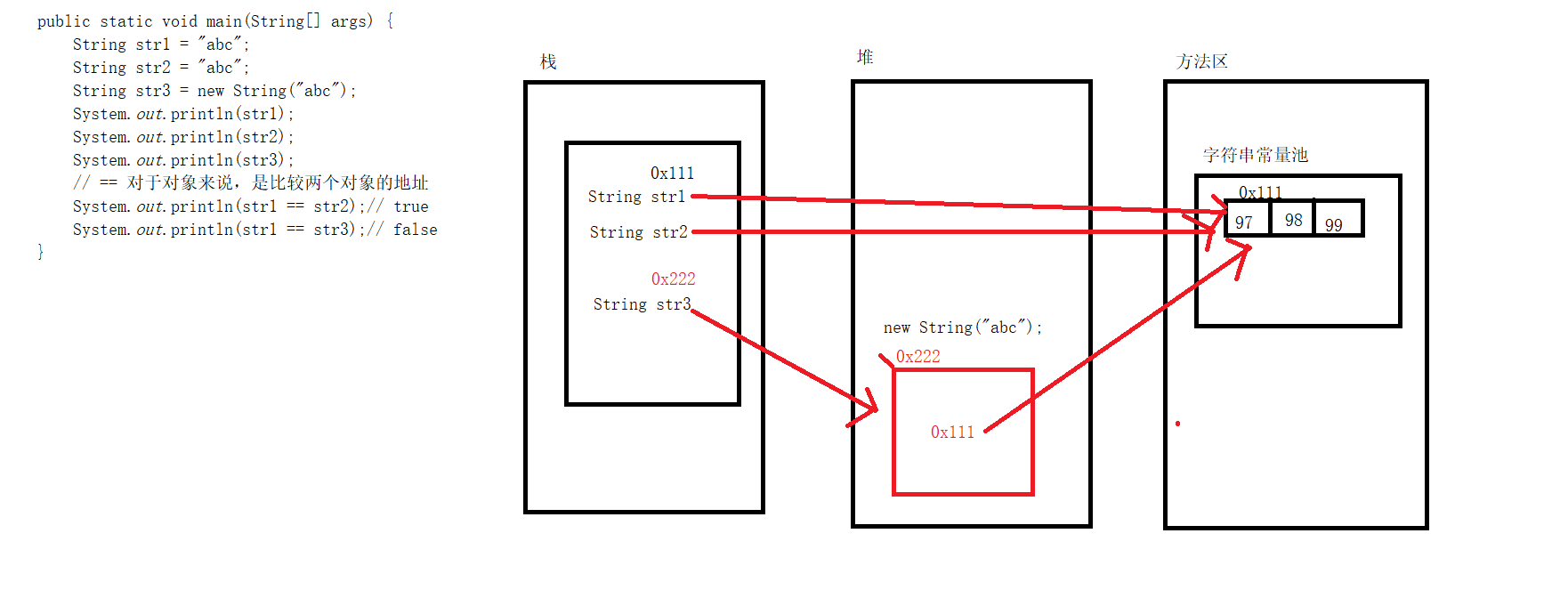
-
如图所示,当我们使用 String str1 = "abc"和String str2 = "abc"时,程序编译时会在方法区建立一个字符串常量池,他是一个数组,由于str1和str2都都指向相同的值"abc",他们的地址是相同的
-
而当使用new String("abc")方式创建对象,会在堆内存中新建一个String对象,而后再栈内存中新增一个对该String对象的引用,而后堆内存新的String对象指向方法区中的字符串常量池,因此即使对象的值相同,由于实现方式不同,他们的地址自然是不同的
-
虽然String类被final修饰,它的String对象在创建后不可被改变,但这不代表string对象不可以被改变(注意我描述的"String"和"string"的首字母大小写不同),当我们对已经创建好的字符串重新赋值时,宏观表现是改变了string对象的值,而实际上我们只是改变了他的引用,让我们将字符串string从"abc"改为"def"时,实际是在字符串常量池中新增了"def",并将当前字符串指向其引用,而原来创建的"abc"字符串对象仍然存在于字符串常量池中
-
字符串可以被共享
字符串的内容实际保存在字符串常量池中,且每个字符串都是唯一的,实际当我们声明字符串变量和赋值时,只是新建/改变了对象指向字符串常量池中的引用 -
字符串底层是字节数组
Java中的String类表示的是一系列字符序列,底层使用字符数组存储这些字符。Java中的字符是基于Unicode编码的,也就是每个字符占用两个字节,即char类型,而从JDK9开始,字符串底层发生了改变,从这个版本开始,字符串底层由字符数组更改为字节数组-
字符数组(char[])的好处是支持多国语言,因为char类型在java中是16位无负数的整数,可以存储UniCode编码的大部分字符(Java中默认编码为UTF-16,每个字符占用16位,也就是两个字节),对于需要更多比特数表示的字符(如某些汉字),Java 使用代理项对来表示这些字符,这样就可以在保持 char 类型固定大小的同时支持所有 Unicode 字符。
根据String类的底层源码可知,在创建char[]数组的同时,还会创建一个int类型的值用来记录数组索引。
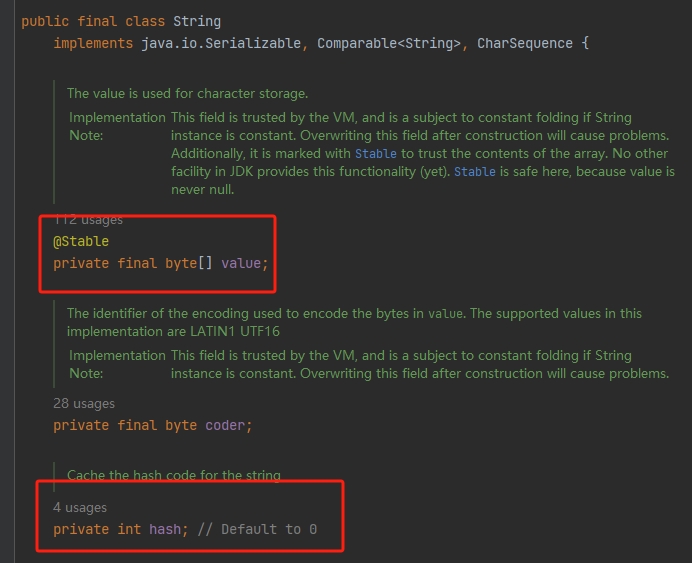
-
尽管 String 类内部使用 char 数组来存储字符,但在某些情况下,需要将字符串转换为字节数组,以便进行网络传输、文件读写等操作,我们通常使用getBytes() 方法:
String str = "hello world"; byte[] bytes = str.getBytes("UTF-8"); // 使用 UTF-8 编码 -
-
在Java设计之初,作者就考虑到了Java底层和多语言支持的多方面因素,选择字符数组作为字符串的底层,但随着发展,为了数据更好的存储、传输,我们现在采用字节数组来代替字符数组
字节数组的优点:
1.在处理ASCII字符集时,ASCII码只占一个字节的存储空间,而char类型在Java中是固定的16位,占用两个空间。同时字节数组可以保存多种编码格式的字符,UTF-8 是一种可变长度的编码,其中ASCII字符仍然只需要一个字节,而UniCode中可能需要更多的字节空间。
2.许多外部系统、协议和文件格式都基于字节流设计,在网络通信中,通常需要将数据使用字节数组进行传输,接收然后再反序列化为字符串,涉及到文件读写时,将数据序列化为字节数组通常比直接处理字符数组更快。
3.相较于字符数组主要用来存储字符,字节数组可以用来存储除此以外的图片、视频、音频等数据,拥有更多用途和扩展性。